[Object Detection] 객체 탐지, 물체 인식, 오브젝트 디텍션?
작년 이상탐지 프로젝트를 진행한 이후, 컴퓨터 비전 공부를 최근 다시 하고 있다.
수업에서 다룬 내용과 수강생들이 프로젝트 주제로 삼았던 것들은 대부분 classification task에 관련된 것들이었으나,
최근에는 Computer vision에서 매우 중요한 task인 object detection을 중점적으로 보고 있다.
아예 비전공자이신 분들이 무슨 공부를 하는거냐, 무슨 일을 하는거냐고 질문하시면 재치있게 답변하기 위해서 이렇게 말한다.
"드라마 스타트업에서 남주혁이 하는 그 일이요~"
사실 스타트업을 안봐서, 세부적인 내용은 잘 모르지만, 하여튼 pedestrian detection 내지는 object detection을 하는 것은 대충 알겠다.
그렇다면, Object Detection에 대해 자세히 살펴보자!
Object detection이란 입력되는 이미지나 영상에 대해, 해당 이미지/영상에 있는 객체들이 뭔 지를 각각 분류하고, 그리고 객체 위치까지 파악해주는 task다. 즉, classification과 localization task가 모두 합쳐진 작업이다. 여기서 localization은 바운딩 박스 좌표값들의 regression이라고 볼 수 있다.
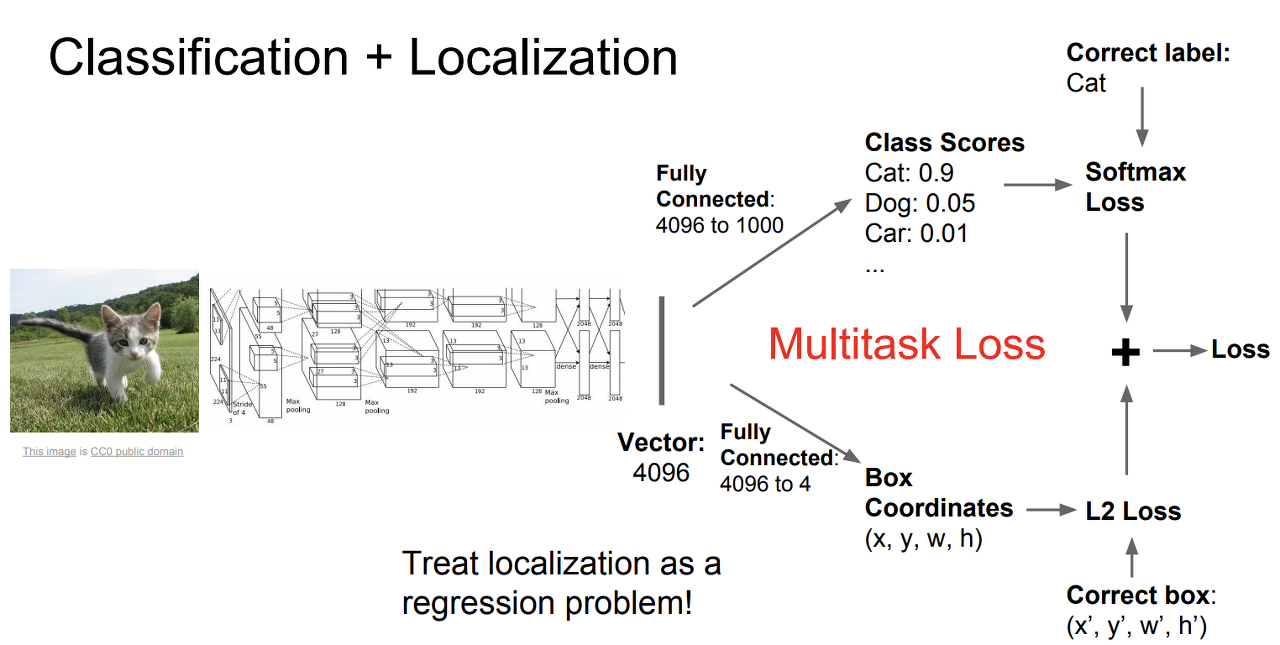
Classification은 분류 문제이므로 softmax loss를 (일반적으로) 활용할 테고, Localization은 회귀 문제이므로 L2 loss와 같은 연속적인 수에 대한 loss function을 활용할 것이다. 두 task를 합치기 위해서는, multitask loss라는 것을 활용하는 데, 어려운 것이 아니고 그냥 앞의 두 loss를 합쳐서 사용한다.
명확히 말하면 사실 localization은 이미지에 물체가 하나일 때의 task를 말한다. Object Detection은 여러 물체에 대해서 이야기하기 때문에, 훨씬 더 어려운 task이다. 또한 정해진 물체의 개수도 없기 때문에, 어떤 이미지에는 1개일 수도, 어떤 이미지에는 100개일 수도 있다. 내가 현재 다루고 있는 데이터 셋에는 0개인 경우도 있었다.
1-stage Detector vs. 2-stage Detector
Object Detection은 크게 두 갈래로 나뉘어 발전했다. 간단히 말하면, 2-stage detector는 물체가 있을 법한 곳을 추정한 후, 그 영역에서 집중적으로 객체를 찾고 분류하는 것이다. 두 작업이 순차적으로 이루어진다. 반면, 1-stage는 두 작업이 동시에 이루어지기때문에, 속도가 훨씬 빨라진다.
- 2-stage Detector
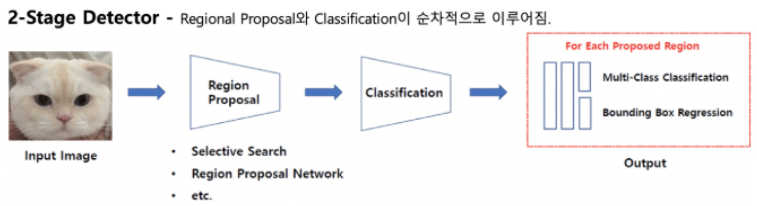
우선 1차원적으로 생각해보자. 이미지가 있는데, 이미지의 모든 픽셀 혹은 모든 그리드를 전부 다 자세히 살펴볼 필요는 없다. 이미지에서도 배경인 부분이 있고 객체가 놓인 부분이 있을테니 객체 부분을 집중적으로 살펴보는 것이 훨씬 효율적일 것이다. 따라서 객체가 있을 법한 영역 즉, 후보들을 미리 선정해둔다. 이것을 Region Proposal이라고 한다. 여기서 선택된 n개의 리전 후보들을 각각 CNN 어떤 백본에 넣어서 각각에 대해 classification을 수행하는 것이다. 그 이후에 실제 오브젝트 위치에 가까워지도록 regression을 진행한다. 느릴수밖에 없는 구조다.
R-CNN계열이 2-stage detector에 해당한다. 2014년에 등장한 R-CNN, 이후 등장한 SPPNet 그리고 Fast R-CNN, Faster R-CNN이 있다. 계속해서 속도를 개선해나갔지만, 실시간 수행을 필요로하는 니즈를 만족시키기는 어려웠다.
- 1-stage Detector
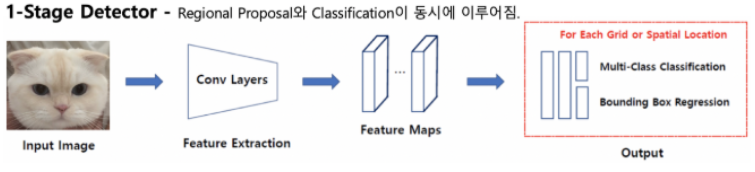
1-stage detector는 region proposal과 classification을 동시에 하는 것이다. 즉, CNN 어떤 백본에 이미지를 통채로 input시켜서 어떠한 feature들을 추출하고, 만들어진 feature map으로 일련의 작업들을 거쳐 classification과 bbox regression을 진행한다. 리전마다 CNN을 돌리지않아도 되기때문에, 속도가 훨씬 빨라졌다.
1-stage detector를 하면 YOLO가 먼저 떠오른다. 2016년에 혜성같이 등장한 조셉 레드몬의 YOLO. 혁신적이었고, 그리고 FPS를 놀라울정도로 낮췄으며 버전이 업그레이드되면서 mAP도 크게 증가했다.
FPS(Frame Per Second)
다음은 object detection의 metric중 하나인 FPS다. 초당 몇 개의 frame이 처리되는지를 나타내는 단위이다. 하루종일 걸려서 detect를 하는 것은 의미가 없기때문에, 속도도 중요한 detection metric이다. (30 FPS가 넘으면 실시간이 가능한 알고리즘으로 판단한다.)
mAP(mean Average Precision)
\(AP = {1 \over 11}\) * \((mp(r=0) + mp(r=0.1) + ... + mp(r=1))\)
Average Precision은 pr그래프에서, recall을 조금씩 증가시키면서, 그 때마다의 precision값을 계산해서 평균을 낸다. 클래스마다의 AP를 계산하며, mAP는 모든 클래스의 AP값들을 평균낸 것이다. 내가 본 논문들은 주로 COCO 데이터셋을 활용해서, 80개에 대한 모든 AP값을 제공하는 대신, mAP값만 제공하고 있었다.
References
그 유명한 스탠포드대학의 cs231n에서 object detection을 다루는 렉쳐다. 공개된 17년도 수업에서는 컴퓨터비전 소개를 하면서 핵심을 짧게 설명하기때문에, 감을 잡을 때 듣기 좋다. 해외 수업을 들으면, 학생들이 질문을 많이 해서 내가 궁금했던 점이나 놓쳤던 부분들을 보충하기에 좋다.
이건 Justin Johnson교수가 미시간대학에서 강의하는 EECS 498-007 / 598-005 수업이다. 이 수업은 오브젝트 디텍션 자체를 한 렉쳐 통채로, 훨씬 자세히 다룬다.
hoya012/deep_learning_object_detection
A paper list of object detection using deep learning. - hoya012/deep_learning_object_detection
github.com
프로젝트를 하면서, 수아랩 리서치 블로그를 많이 참고했었다. 현재는 코그넥스지만! 하여튼 그렇게 알게된 블로그 및 이 호성님. 블로그와 깃허브, 하셨던 논문 리뷰 영상 등등으로 정말 많은 도움을 얻고있다. 위의 깃허브 레포에서는 딥러닝기반의 오브젝트 디텍션 알고리즘(논문)들을 흐름별로 정리하시고, 성능별로 비교되어있다.
더 자세하고 다양한 내용들은 각 알고리즘과 모델들에 대한 개별 글로 설명하도록 하겠다.